近日,实验室2024级硕士生范佳奕一篇论文“SPOT: Spatiotemporal Prompt Optimization for Motion-Stabilized MLLM-Guided Video Segmentation”(作者:范佳奕,秦者云,袭肖明,聂秀山,尹义龙)被CVPR2026会议录用。CVPR是国际计算机视觉顶尖和权威学术会议之一,属于CCF A类会议。
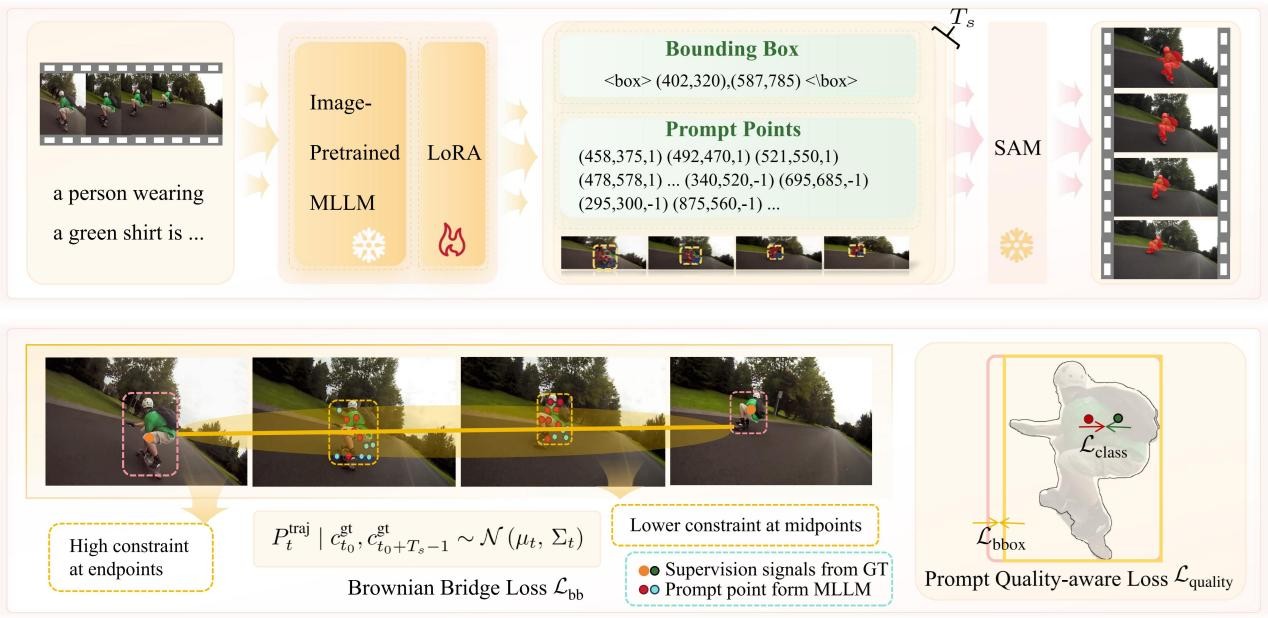
多模态大型语言模型(MLLM)与视觉基础模型的协同框架在图像理解任务中展现出卓越的性能,但在视频分割场景中却面临着严重的时序不一致性挑战。现有方法主要依赖于在静态图像上训练的MLLM来生成逐帧分割提示,忽略了视频运动的物理连续性。本文认为,视频理解任务的性能瓶颈源于对模型输出行为约束不足。因此,我们提出了一种时空协同优化机制,该机制仅通过约束MLLM的输出行为即可实现时间一致的视频分割,无需大规模视频预训练或复杂的架构修改。我们的方法包含两个互补的机制:布朗桥损失,将目标轨迹建模为端点约束的高斯过程以确保时间平滑性;以及几何感知提示质量损失,强制执行与目标结构的空间一致性。在指称表达视频分割(Referring Expression Video Segmentation)和推理视频分割(Reasoning Video Segmentation)任务上的实验表明,我们的方法在 Ref-YouTube-VOS、Ref-DAVIS-2017、MeVIS、A2d-Sentences、JHMDB-Sentences 和 ReVOS 基准测试中显著优于现有技术。这项工作证明,显式地对物理世界约束进行建模可以充分发挥静态训练的基础模型在动态视觉理解任务中的潜力。